Separable neural representations of sound sources: Speaker identity and musical timbres
Abstract
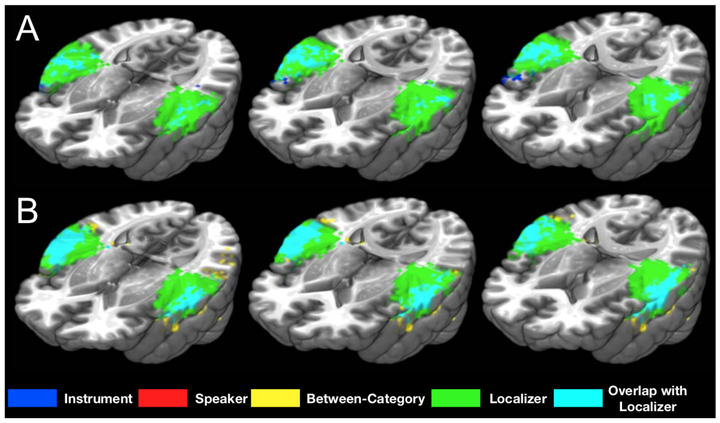
Human listeners can quickly and easily recognize different sound sources (objects and events) in their environment. Understanding how this impressive ability is accomplished can improve signal processing and machine intelligence applications along with assistive listening technologies. However, it is not clear how the brain represents the many sounds that humans can recognize (such as speech and music) at the level of individual sources, categories and acoustic features. To examine the cortical organization of these representations, we used patterns of fMRI responses to decode 1) four individual speakers and instruments from one another (separately, within each category), 2) the superordinate category labels associated with each stimulus (speech or instrument), and 3) a set of simple synthesized sounds that could be differentiated entirely on their acoustic features. Data were collected using an interleaved silent steady state sequence to increase the temporal signal-to-noise ratio, and mitigate issues with auditory stimulus presentation in fMRI. Largely separable clusters of voxels in the temporal lobes supported the decoding of individual speakers and instruments from other stimuli in the same category. Decoding the superordinate category of each sound was more accurate and involved a larger portion of the temporal lobes. However, these clusters all overlapped with areas that could decode simple, acoustically separable stimuli. Thus, individual sound sources from different sound categories are represented in separate regions of the temporal lobes that are situated within regions implicated in more general acoustic processes. These results bridge an important gap in our understanding of cortical representations of sounds and their acoustics.